- Products
-
Resources


Results Foundry

- Company
- Log in Request a Demo
Results Foundry
Bhavin Vyas is the VP of Data Science and Engineering at WorkBoard. With over 25 years in technology, his data journey started with analyzing code performance 20+ years ago, before expanding into larger data mining projects at Google to help improve Google's ad quality. He also used machine learning to personalize music at SpeakMusic, an AI voice-assistant startup.
At WorkBoard, we started exploring AI very early, but as Daryoush Paknad, our CTO, mentioned in his post, the technology wasn't ready then. When advanced models became available, we jumped at the opportunity to drive value for our users. My experience spanning optimization, ad quality, and music personalization prepared me to quickly drive new AI advancements at WorkBoard for enterprise impact.
The first problem we set out to solve was finding Key Results semantically similar to others across large organizations. We were aware that by manually identifying duplicate and aligned work, our clients had achieved significant improvement in cross-team collaboration on major initiatives, and increased productivity by reducing duplicate efforts. Now, we set out to do exactly that – but automatically, using Gen AI.
With annual transactions surpassing 2.5 billion, we have accumulated the largest and highest-quality dataset in the strategy execution space. We were confident that this massive trove of data, combined with our technical expertise gathered over the years, allowed us to surface impactful insights for our customers.
By leveraging Semantic Similarity search with a human-in-the-loop approach, we enable users to easily discover patterns and meaningful connections in their execution strategies.
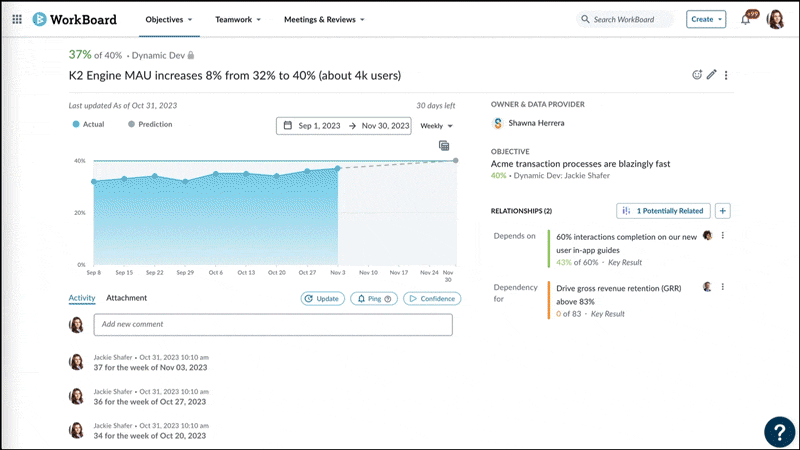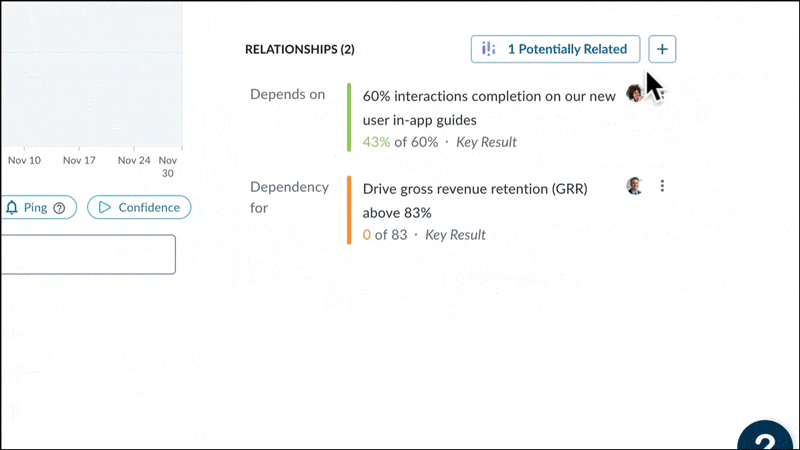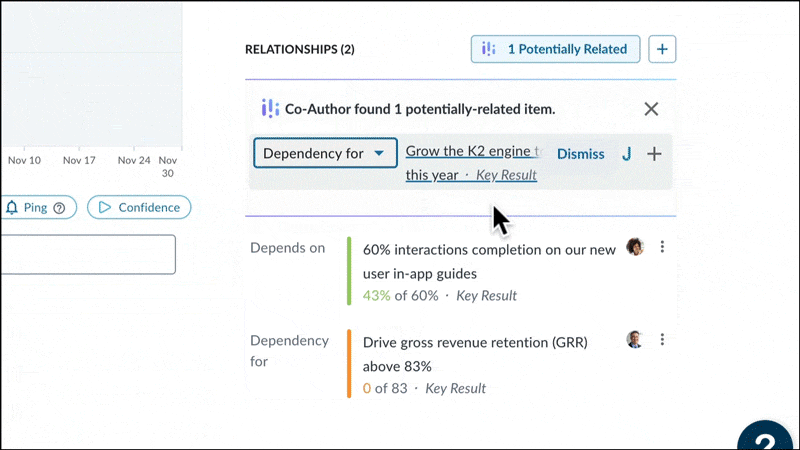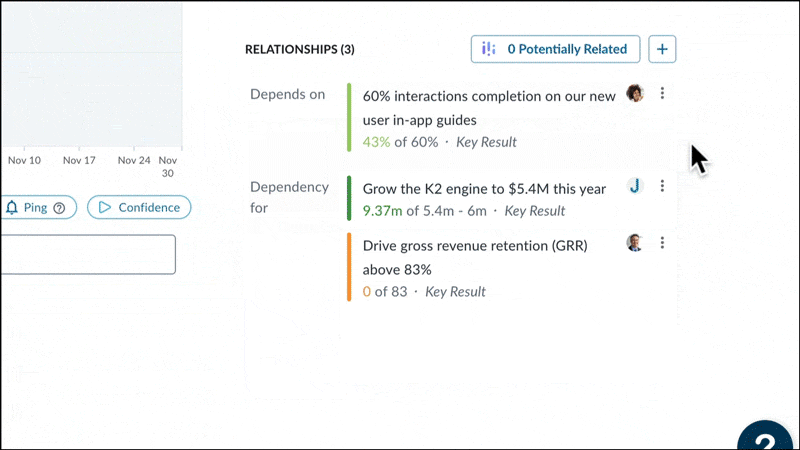
Keyword search looks for overlapping terms, but this can miss conceptually similar content using different words. Semantic search looks for meaning behind the words. For example, take these two business key results:
Though they use different terms, our semantic search understands these Key Results express similar intent. Keyword search would miss this connection.
By evaluating overall meaning, not just keywords, we surface overlooked but relevant matches between disconnected content in an organization. This reveals new connections and opportunities.
What is happening behind the scenes is that an ML model that understands natural language converts each Key Result into a Vector based on its semantic meaning. The more similar the two statements are, the closer they live in Vector space. Open AI embeddings are 1536 dimensions (instead of 2 dimensions on a X-Y graph) - so there’s a lot of virtual space to distribute different vector representations. Let’s now understand bit about Embedding, also known as Vectorization.
Vectorization converts text into numerical representations called vectors. Each vector represents the semantic meaning of the text as coordinates in multi-dimensional space.
Even when Key Results use different words, their vector representations reflect their semantic meaning.
After vectorizing large amounts of text data, we can find vectors clustered close together in the vector space. This proximity indicates semantic similarity, despite differences in terminology.
Through extensive testing, we found the latest GPT-3.5 model provides the most advanced vectorization for our natural language processing needs and thus most accurately represent text meaning to enable strong semantic search capabilities.
Embedding ML models do not store vector representation, they simply give you the vector representation, based on intent, of a piece of text. Vector Databases complement them and allow efficient storage and speedy retrieval of vector representations of text data. This provides the foundation for powerful semantic search capabilities.
After evaluating many Vector Database options, we selected Weaviate for its performance and scalability (a close second was Pinecone). We valued Weaviate's usage-based pricing, hybird search architecture and open-source availability.
By leveraging a Vector Database, we can deliver fast and accurate semantic search to business users. This transforms how enterprises analyze unstructured text data to unlock new insights.
Protecting client data is our top priority in all technological decision making. We designed our architecture to safeguard security and privacy while delivering robust capabilities.
We minimized reliance on third-party vendors, instead keeping as much in-house as possible. When external tools are required, like a vendor for Vector Database, we rigorously vet providers based on stringent standards compliance, security policies, and proven track records with sensitive data.
Specifically, we looked at areas like standards compliance (SOC2, SOC3, ISO27001, TSAX), data management policies, security, financial strength (investors and length of time in business are good proxies), existing clients and more.
Let's talk about similarity scores a little. Our vector database returns a similarity score between 0-1 for suggested semantic matches. A score of 0 indicates identical statements. The closer to 0, the more similar the meaning, even if the wording differs.
For example: "Increase customer retention" may score 0.05 when matched to "Improve customer loyalty metrics."
We can filter matches based on a threshold score that provides the most useful, relevant results. Through analyzing user behavior, we determine optimal thresholds for different use cases.
Setting a maximum threshold of 0.15 would return highly similar statements, while 0.4 would include more loosely related content. The appropriate threshold depends on the specific business need.
By tuning these similarity score thresholds, we can refine search relevancy and quality over time based on data and feedback.
Note: different Vector DBs represent scores differently. E.g.: Pinecone also has a 0 to 1 range, but counts a score of 1 as most similar in meaning.
My top 3 learnings about the Applied Generative AI space so far are:
Like it? Share it with your network!

As a seasoned tech founder, WorkBoard CTO and Co-Founder Daryoush Paknad has participated in several major technology shifts, from mainframes to client server, from data centers to cloud computing and more. Now he reflects on how artificial intelligence is transforming the workplace.

Getting everyone aligned on results going into next quarter is much faster and more fun with genAI in WorkBoard Co-Author. Learn how Co-Author can help teams quickly get to agreement on their best outcomes.

This breakthrough in strategy execution ushers in a new era of high focus, efficiency, and agility for large enterprises that must execute well in dynamic markets despite resource constraints.





